Code, Build, and Deploy
OpenShift and GitLab CI/CD can build and deploy your apps automatically, so you can stay focused on writing code.
Releasing software is usually a time-consuming and cumbersome process for developers. OpenShift [1], an open source container application platform, paired with the GitLab continuous integration and continuous delivery (CI/CD) tool [2] can help developers be more productive by improving software release cycles.
OpenShift provides a self-service platform that allows you to create, modify, and deploy applications on demand, thus enabling faster development and release life cycles. With these tools, developers can be more focused on application development than on the operational details.
With this article, I aim to demonstrate how to set up a CI/CD process quickly on OpenShift and how to integrate it into developer workflows. In the end, you will have all the information you need in hand to create an application that is built and deployed automatically at each commit.
Containerized Presentation
As an example for this article, I adapt one of my recent projects, in which I presented the OpenShift platform to my colleagues at CETIC [3]. CETIC is an applied research center for information and communication technologies and develops its expertise in key technologies, including Big Data, cloud computing, the Internet of Things, software quality, and IT systems trust and security. What better way to present OpenShift and illustrate the CI/CD workflow than to present several slides, written with the reveal.js [4] framework, which I used to create a presentation using HTML, and then containerized and deployed by OpenShift with the help of a Docker Node.js image.
The CI/CD process presented here allows you to build and deploy slides automatically with OpenShift on every new commit in the Git repository. The slides are available online [5] and the source code of this example is available at the CETIC Git repository [6].
To begin, I’ll define the tools used and describe the setup needed to make this CI/CD process available. At the end of this article, you can find the final results.
OpenShift for CI/CD Setup
OpenShift Origin is a Platform as a Service (PaaS) offered from Red Hat for container-based software deployment and management. It brings together the Docker containerization tool [7] and the Kubernetes orchestration tool [8], as well as the DevOps tools for accelerated application development like source-to-image (S2I) [9], which I use in this example.
To begin, you need an OpenShift cluster and a project. For this tutorial, I use OpenShift Origin v3.6. For interested readers who don’t have an OpenShift Origin cluster, you can instead use Minishift [10], a tool that runs a single-node OpenShift cluster locally inside a virtual machine (VM). Next, create a new project on OpenShift in the user interface, as shown in Figure 1; I refer to this project as slides-openshift .
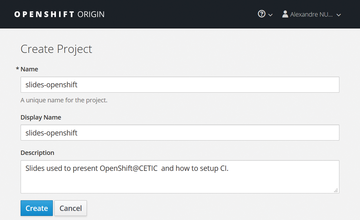
Figure 1: Create a new project in the OpenShift user interface.
{kind=link}
Now you need to create a service account (Resources | Membership | Service Accounts ) to connect GitLab CI to the slides project on OpenShift (Figure 2). A service account is simply another flexible way to control API access without sharing a regular user’s credentials [11]. The name for this example service account is gitlab-ci . Because each service account is unique, you need to create a new one for each new project. So you can create and edit project resources, you should add the edit role to your gitlab-ci service account.
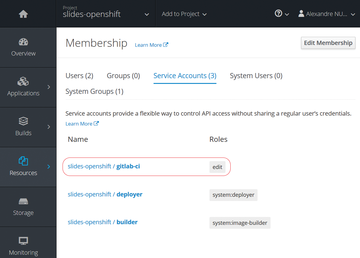
Figure 2: Create a new service account on OpenShift with the edit role.
{kind=link}
In Figure 2 you can also see two other default service accounts: the deployer role and the builder role. The deployer role allows you to push images to any image stream in the project using the internal Docker registry, and the builder role allows you to view, modify, and scale containerized applications in the project. Listing 1 shows how you can also create a service account at the command line with the OpenShift client.
Listing 1
Creating a Service Account
# enter the slides project oc project slides-openshift # create the service account oc create sa gitlab-ci # add edit role to service account oc policy add-role-to-user edit system:serviceaccount:slides-openshift:gitlab-ci
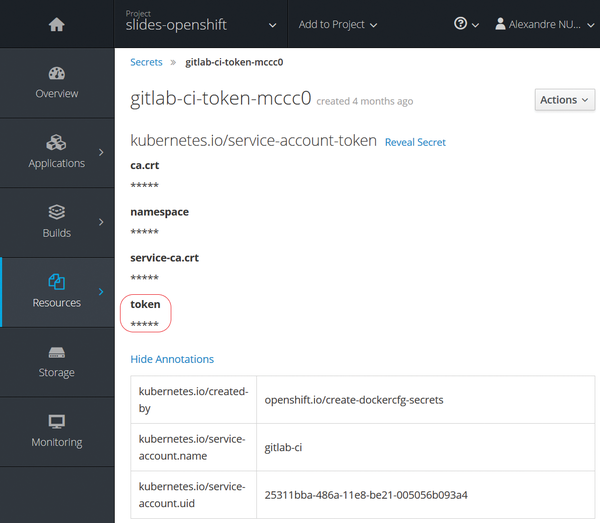
Once the service account is created, you should retrieve the secret token (Resources | Secrets ), so external applications can authenticate through the OpenShift API (Figure 3). This token will be used in the GitLab CI section.
Figure 3: Retrieve the secret token on OpenShift.
{kind=link}
At this level, OpenShift is set up and ready to be integrated with GitLab CI for configuration of the CI/CD process. You can thereafter explore all the potential that the OpenShift platform offers. For instance, you can scale your application up and down through the user interface or even scale automatically according to CPU usage.
GitLab CI
For this project I use GitLab CI v11.1.4. The goal of continuous integration in the development timeline is to reduce the time needed for developers to test code modifications. Most projects usually use GitLab CI to run test suites for immediate feedback.
To activate GitLab CI, you add a YAML gitlab-ci file (described later in the article) to the root directory of your Git repository. Once activated, each commit on the repository will trigger your CI/CD pipeline. By default, it runs a pipeline with three stages: build , test , and deploy (Figure 4).
Figure 4: The default GitLab CI/CD pipeline (image source: GitLab Docs [12]).
{kind=link}
Every commit pushed to GitLab generates and attaches a pipeline, which is a collection of jobs split into different stages, as described in the gitlab-ci YAML file. These stages are just logical divisions between job batches, wherein a subsequent job does not execute if the previous job fails. It doesn’t make much sense to deploy something that failed to build. No job should have a dependency with any other job in the same stage, although a job can expect results from jobs in previous stages.
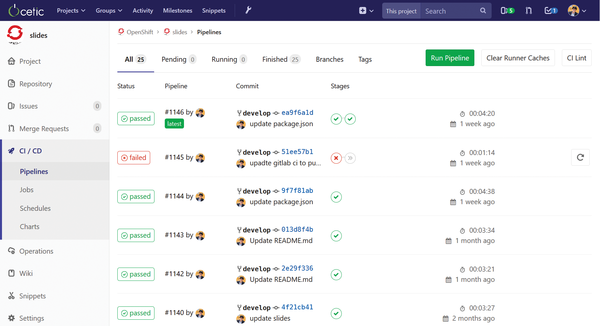
As you will see in the next section, I only set up one stage, but test and build stages could be added. For instance, Figure 5 gives you a good idea of how pipelines look on GitLab, with a pipeline status for each commit; you can see, for example, that pipeline #1145 failed, whereas #1144 succeeded.
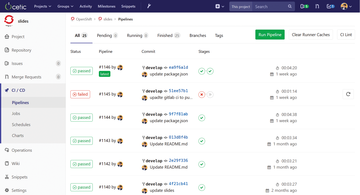
Figure 5: GitLab CI pipeline status for each commit.
{kind=link}
To execute the script in the gitlab-ci file, you need to configure your GitLab project to use a runner, which is basically a server that executes instructions listed in the gitlab-ci file and reports the result back to GitLab.
Several GitLab Runner executors exist that can run your builds, depending on you scenario [13]. The simplest is probably the shell executor, because it executes builds locally to the machine where the Runner is installed, on which you need to install all required dependencies for your builds manually.
An easier way is to use the Docker executor, which allows a clean build environment with easy dependency management. Indeed, all dependencies for building the project could be put into the Docker image. Once the script terminates, the Docker image is automatically deleted. This type of executor has been chosen for the example in this article.
A Shared Runner simply means that it can be used by other developers for other projects, whereas a Specific Runner is useful for jobs that have special requirements or for projects with specific demands. Interested readers can set up their own Shared or Specific Runner on OpenShift by following a tutorial online [14]; it is the method used for this example.
Once your Runner is installed, you should keep in mind the tag you gave to your Runner during the installation – in this case, docker (Figure 6).
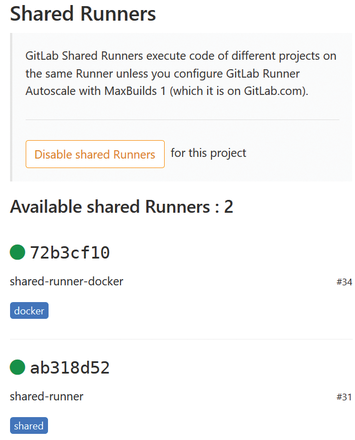
Figure 6: Available Shared Runners on GitLab.
{kind=link}
Now that your GitLab repository is well configured, it is time for you to create the gitlab-ci file to set up the CI/CD process for the slides example that I mentioned earlier.
On any commit to your repository, GitLab will look for this file and start jobs on a Runner. To activate the CI/CD process, access your repository and simply click on Setup CI/CD . Then, GitLab provides a number of templates that can be reused for your gitlab-ci file.
For this tutorial, I use a predefined gitlab-ci template file for OpenShift that helps me quickly configure the CI/CD process. This template is available online [15], or it can be found by clicking on Setup CI/CD and selecting the OpenShift template.
You will need to modify the gitlab-ci file described in the template for your CI/CD pipeline to work (Listing 2). The important thing to remember is to add the tag you have already defined in the GitLab Runner step to your own gitlab-ci file. By adding this tag, you specify that your CI/CD process has to be executed by the Shared Runner with the Docker executor. This tag allows you to start jobs with the Runner that has the specified tag assigned to it.
The tag’s specification must be set under a job (in this case, under the develop job in line 29). It will make sure the job is built by the Runner defined by the docker tag. As you can see in Listing 2, the beginning of the file starts by using a Docker image in which the script will be executed. Here, I use the openshift-client Docker Alpine image [16] with the OpenShift client already installed.
Listing 2
Slides Project gitlab-ci File
01 image: ebits/openshift-client 02 03 stages: 04 - deployToOpenShift 05 06 variables: 07 OPENSHIFT_SERVER: https://openshift.ext.cetic.be:8443 08 OPENSHIFT_DOMAIN: openshift.ext.cetic.be 09 # Configure this variable in Secure Variables: 10 # OPENSHIFT_TOKEN: my.openshift.token 11 12 .deploy: &deploy 13 before_script: 14 - oc login "$OPENSHIFT_SERVER" --token="$OPENSHIFT_TOKEN" --insecure-skip-tls-verify 15 # login with the service account 16 - oc project "slides-openshift" 17 # enter into our slides project on OpenShift 18 script: 19 - "oc get services $APP 2> /dev/null || oc new-app . --name=$APP" 20 # create a new application from the image in the OpenShift registry 21 - "oc start-build $APP --from-dir=. --follow || sleep 3s" 22 # start a new build 23 - "oc get routes $APP 2> /dev/null || oc expose service $APP --hostname=$APP_HOST" 24 # expose our application 25 26 develop: 27 <<: *deploy 28 stage: deployToOpenShift 29 tags: 30 - docker 31 variables: 32 APP: slides-openshift 33 APP_HOST: demo-slides.$OPENSHIFT_DOMAIN 34 environment: 35 name: develop 36 url: http://demo-slides.$OPENSHIFT_DOMAIN 37 except: 38 - master
Next, you need to configure the OpenShift secret token you retrieved into the secure variables of your project in GitLab. The secret token will be used to authenticate your Runner to OpenShift on the login command line (line 14).
To do so, go into Settings , in the GitLab CI user interface, and add your variable OPENSHIFT_TOKEN. Also, do not forget to configure the OPENSHIFT_SERVER variable with the URL of your OpenShift instance (line 7) and the OPENSHIFT_DOMAIN variable (line 8) in the gitlab-ci file.
You can also update the APP and APP_HOST variables with the name of your application (lines 32 and 33). In this example, I assign slides-openshift for the application name (by default, the template uses the OpenShift project name) and demo-slides.$OPENSHIFT_DOMAIN for the URL.
These are the only modifications required to get a CI/CD pipeline running, but you can consider other modifications, such as setting a deployment strategy, depending on the branch to which the developer pushes the code.
For instance, I could have a production environment for the master branch and a development environment for the other branches, or I could add more phases in the CI/CD process, such as quality checks, test suites, and so on.